
Строки и символы
Строка представляет собой совокупность символов, например "hello, world" или "albatross". Строки в Swift представлены типом String. К значению типа String можно получить доступ различными способами, включая и коллекцию значений типа Character.
Типы String и Character в Swift предусматривают быстрый, Unicode-совместимый способ работы с текстом в вашем коде. Синтаксис для создания и манипулирования строками легкий и читабельный, он включает синтаксис строковых литералов похожий на С. Конкатенация строк так же проста, как сложение двух строк с помощью оператора + , а изменчивостью строки можно управлять выбирая к чему присваивать значение, константе или переменной, также как в случае с любым другим значением в Swift. Вы также можете использовать строки для вставки констант, переменных, литералов и выражений в более длинные строки- процесс, известный как интерполяция строк. Это позволяет легко создавать пользовательские значения строк для отображения, хранения и вывода информации.
Несмотря на эту простоту синтаксиса, тип String в Swift имеет быструю и современную реализацию. Каждая строка состоит из независимых от кодировки символов Unicode, и обеспечивает поддержку доступа к этим символам в различных Unicode представлениях.
Заметка
Тип String в Swift бесшовно сшит с классом NSString из Foundation. Если вы работаете с фреймворком Foundation в Cocoa или Cocoa Touch, то весь API NSString доступен для каждого значения типа String создаваемого вами в Swift, включая все возможности String, которые описываются в этой главе. Вы также можете использовать значение с типом String для любых API, в которых используется NSString. Для получения дополнительной информации об использовании String с Foundation и Cocoa, обратитесь к книге "Использование Swift с Cocoa и Objective-C".
Строковые литералы
Вы можете включить предопределенные String значения в вашем коде как строковые литералы. Строковый литерал - это фиксированная последовательность текстовых символов, окруженная парой двойных кавычек ("").
Используйте строковый литерал как начальное значение для константы или переменной:
let someString = "Some string literal value"Заметьте, что Swift вывел тип String для константы someString, потому что он был инициализирован строковым литеральным значением.
Многострочные литералы строк
Если вам нужно создать строку, которая поддерживает многострочный вид, используйте литерал многострочной строки - последовательность символов, обернутых в три двойные кавычки:
let quotation = """
The White Rabbit put on his spectacles. "Where shall I begin,
please your Majesty?" he asked.
"Begin at the beginning," the King said gravely, "and go on
till you come to the end; then stop."
"""Многострочный литерал строки включает в себя все строки между открывающими и закрывающими кавычками. Строка начинается на первой строке после открывающих кавычек ("""), а заканчивается на строке предшествующей закрывающим кавычкам, что означает, что ни одна из строк ниже ни начинается, ни заканчивается символом переноса строки:
let singleLineString = "These are the same."
let multilineString = """
These are the same.
"""Когда ваш исходный код включает в себя символ переноса строки внутри литерала многострочной строки, то этот символ переноса строки так же появляется уже внутри значения этой строки. Если вы хотите использовать символ переноса строки для того, чтобы сделать ваш код более читаемым, но вы не хотите чтобы символ переноса строки отображался в качестве части значения строки, то вам нужно использовать символ обратного слеша (\) в конце этих строк:
let softWrappedQuotation = """
The White Rabbit put on his spectacles. "Where shall I begin, \
please your Majesty?" he asked.
"Begin at the beginning," the King said gravely, "and go on \
till you come to the end; then stop."
"""Для того, чтобы создать литерал строки, который начинается и заканчивается символом возврата каретки (\r), напишите пустую строчку в самом начале и в конце литерала строки, например:
let lineBreaks = """
This string starts with a line break.
It also ends with a line break.
"""
Многострочная строка может иметь отступы для соответствия окружающему ее коду. Пробел до закрывающей группы двойных кавычек (""") сообщает Swift, сколько пробелов нужно игнорировать в начале каждой строки. Если же вы напишите дополнительные пробелы напротив какой-либо строки к тем, которые стоят напротив закрывающих кавычек, то эти дополнительные пробелы уже будут включены в значение строки.
let linesWithIndentation = """
Эта строка начинается без пробелов в начале.
Эта строка имеет 4 пробела.
Эта строка так же начинается без пробелов.
"""В примере выше, не смотря на то, что весь литерал многострочной строки имеет отступ, первая и последняя строка будут начинаться без пробелов. Средняя же строка будет иметь отступ, так как она начинается с дополнительными четырьмя пробелами относительно закрывающей группы двойных кавычек.
Специальные символы в строковых литералах
Строковые литералы могут включать в себя следующие специальные символы:
- экранированные специальные символы \0 (нулевой символ), \\ (обратный слэш), \t (горизонтальная табуляция), \n (новая строка), \r (возвращение каретки), \" (двойные кавычки) и \' (одиночные кавычки )
- Произвольные скалярные величины Юникода, записанные в виде \u{n} , где n - 1-8 значное шестнадцатеричное число со значением, равным действительной точке кода Юникода.
Приведенный ниже код показывает все эти четыре примера специальных символов. wiseWords константа содержит два экранированных символа: двойные кавычки. DollarSign, blackHeart, и sparklingHeart константы показывают скалярный формат Юникода:
let wiseWords = "\"Imagination is more important than knowledge\" - Einstein"
// "Imagination is more important than knowledge" - Einstein
let dollarSign = "\u{24}" // $, Unicode scalar U+0024
let blackHeart = "\u{2665}" // ♥, Unicode scalar U+2665
let sparklingHeart = "\u{1F496}" //  , Unicode scalar U+1F496
, Unicode scalar U+1F496
Так как многострочные строки имеют три двойные кавычки вместо одной, то вы можете включить двойную кавычку внутрь многострочной строки без знака экранирования. Для того, чтобы включить символы """ в многострочную строку, вам нужно экранировать хотя бы одну из кавычек, например:
let threeDoubleQuotes = """
Escaping the first quote \"""
Escaping all three quotes \"\"\"
"""
Расширенные разделители строк
Вы можете поместить строковый литерал внутрь расширенного разделителя, чтобы включить в строку специальные символы, не вызывая эффекта самих символов. Вы помещаете вашу строку в кавычки (") и оборачиваете ее знаками #. Например, при печати строкового литерала #"Line 1\nLine 2"# выйдет последовательность символов с символом новой строки (\n), а не предложение разбитое на две строки.
Если вам нужен эффект специального символа в строковом литерале, сопоставьте количество знаков (#) в строке после символа экранирования (\). Например, если ваша строка #"Line 1\nLine 2"#, и вы хотите перенести часть предложения на новую строку, вы можете использовать #"Line 1\#nLine 2"# вместо этого. Аналогично ###"Line1\###nLine2"### также разрывает строку.
Строковые литералы, созданные с использованием расширенных разделителей, также могут быть многострочными строковыми литералами. Вы можете использовать расширенные разделители для включения текста """ в многострочную строку, переопределяя поведение по умолчанию, которым завершается сам строковый литерал. Например:
let threeMoreDoubleQuotationMarks = #"""
Here are three more double quotes: """
"""#Инициализация пустых строк
Чтобы создать пустое String значение в качестве отправной точки для создания более длинных строк, либо присвойте литерал пустой строки к переменной, либо инициализируйте объект String c помощью синтаксиса инициализации:
var emptyString = "" // empty string literal
var anotherEmptyString = String() // initializer syntax
// обе строки пусты и эквиваленты друг другуМожно узнать пустое ли String значение, через его Boolean свойство isEmpty:
if emptyString.isEmpty {
print("Nothing to see here")
}
// Выведет "Nothing to see here"Изменчивость строк
Вы можете указать, может ли конкретный String быть модифицирован, путем присвоения его переменной ( в этом случае он может быть модифицирован), или присвоения его константе ( в этом случае он не может быть модифицирован):
var variableString = "Horse"
variableString += " and carriage"
// variableString теперь "Horse and carriage"
let constantString = "Highlander"
constantString += " and another Highlander"
// это выдаст ошибку компиляции: строковая константа не может быть модифицированаЗаметка
Этот подход отличается от изменчивости строк в Objective-C и Cocoa, где мы выбираем между двумя классами (NSString и NSMutableString), чтобы указать, может ли строка быть изменена.
Строка является типом значения
Тип String в Swift является типом значения. Когда вы создаёте новое String значение, это значение копируется, когда оно передается функции или методу, или когда оно присваивается константе или переменной. В каждом случае создается новая копия существующего String значения, и передаётся либо присваивается новая копия, а не исходная версия. Типы значений описаны в главе Структуры и перечисления - типы значения.
Подход "копировать по умолчанию" для String в Swift позволяет быть уверенным в том, что когда вы передаете функции либо методу String значение, то очевидно, что вы имеете точно то же String значение, независимо от того, откуда она пришла. Вы можете быть уверены, что строка, которая вам передана, не будет модифицирована, если вы не модифицируете ее сами.
Компилятор Swift оптимизирует использование строк, так что фактическое копирование строк происходит только тогда, когда оно действительно необходимо. Это означает, что вы всегда получаете высокую производительность, при работе со строками, как с типами значений.
Работа с символами
Тип String в Swift представляет собой коллекцию значений Character в указанном порядке. Вы можете получить доступ к отдельным значениям Character в строке с помощью итерации по этой строке в for-in цикле:
for character in "Dog!" {
print(character)
}
// D
// o
// g
// ! Цикл for-in описан в главе Циклы for-in.
Кроме того, можно создать отдельную Character константу или переменную из односимвольного строкового литерала с помощью присвоения типа Character:
let exclamationMark: Character = "!"Значения типа String могут быть созданы путем передачи массива типа [Character] в инициализатор:
let catCharacters: [Character] = ["C", "a", "t", "!"]
let catString = String(catCharacters)
print(catString)
// Выведет "Cat!"Конкатенация строк и символов
Значения типа String могут быть добавлены или конкатенированы с помощью оператора сложения (+):
let string1 = "hello"
let string2 = " there"
var welcome = string1 + string2
// welcome равен "hello there"
Вы можете добавить значение типа String к другому, уже существующему значению String, с помощью комбинированного оператора сложения и присвоения (+=):
var instruction = "look over"
instruction += string2
// instruction равен "look over there"
Вы можете добавить значение типа Character к переменной типа String, используя метод String append:
let exclamationMark: Character = "!"
welcome.append(exclamationMark)
// welcome равен "hello there!"
Заметка
Вы не можете добавить String или Character к уже существующей переменной типа Character, потому что значение типа Character должно состоять только из одиночного символа.
Если вы используете многострочные строковые литералы для построения более длинной строки, то вы захотите, чтобы каждая строка заканчивалась разрывом строки, включая последнюю. Например:
let badStart = """
one
two
"""
let end = """
three
"""
print(badStart + end)
// Prints two lines:
// one
// twothree
let goodStart = """
one
two
"""
print(goodStart + end)
// Prints three lines:
// one
// two
// threeВ коде выше конкантенация badStart вместе с end создают двухстрочную строку, которая имеет не тот результат, на который мы расчитывали. Из-за того, что последняя строка badStart не содержит символа переноса строки, она соединяется с первой строкой end. И наоборот, если оба конца строки goodStart будут заканчиваться символом переноса строки, то результат будет именно тот, что мы и хотим.
Интерполяция строк
Интерполяция строк - способ создать новое значение типа String из разных констант, переменных, литералов и выражений, включая их значения в строковый литерал. Каждый элемент, который вы вставляете в строковый литерал, должен быть помещен в скобки и находиться внутри двойных кавычек литерала, а перед открывающей скобкой должен стоять знак обратного слэша.
let multiplier = 3
let message = "\(multiplier) times 2.5 is \(Double(multiplier) * 2.5)"
// message равен "3 times 2.5 is 7.5"
В примере выше значение multiplier включено в строку как \(multiplier). В свою очередь \(multiplier) заменяется на фактическое значение константы multiplier, когда вычисляется интерполяция строки для создания конечного варианта.
Значение multiplier - это так же часть большего выражения в будущей строке. Это выражение высчитывает значение Double(multiplier) * 2.5 и вставляет результат 7.5 в строку. В этом случае выражение записанное в виде \(Double(multiplier) * 2.5) является строковым литералом.
Заметка
Выражения, которые вы пишете внутри скобок в интерполируемой строке, не должны содержать неэкранированный обратный слэш, символ перевода строки (\n) или символ возврат каретки (\r). Однако выражения могут содержать другие строковые литералы.
Юникод (Unicode)
Юникод является международным стандартом для кодирования, представления и обработки текста в разных системах письма. Он позволяет представлять почти любой символ из любого языка в стандартизированную форму. А также читать и записывать эти символы во внешний источник и из него. К таким источникам относятся, например текстовый файл или веб-страница. Типы String и Character в Swift полностью совместимы с Юникодом, что описано в этом разделе.
Скалярные величины Юникода
Если посмотреть глубже, то можно увидеть, что собственный String тип в Swift построен из скалярных значений (Unicode scalar ) Юникода. Скалярная величина Юникода является уникальным 21-разрядным числом для символа или модификатора, например, U+0061 для LATIN SMALL LETTER A ("a") , или U+1F425 для FRONT-FACING BABY CHICK ().
Заметка
Скалярная величина Юникода - это любая точка кода в диапазоне U+0000 до U+D7FF включительно, или U+E000 до U+10FFFF тоже включительно. Скалярные величины Юникода не включают Юникод суррогатные пары точек кода, т.е. точки кода в диапазоне U+D800 до U+DFFF включительно.
Обратите внимание, что не все 21-битные скалярные величины Юникода присваиваются символу. Некоторые скалярные величины содержатся в резерве для будущего присваивания. Скалярные величины, присвоенные символу, как правило имеют название, например LATIN SMALL LETTER A и FRONT-FACING BABY CHICK, что можно увидеть в примере выше.
Расширяемые наборы графем
Каждый экземпляр типа Character в Swift представляет один расширенный набор графем. Расширенный набор графем является последовательностью одного и более скалярных величин Юникода, которые (будучи объединенными) производят один читаемый символ.
Вот пример. Буква é может быть представлена в виде самостоятельной скалярной величины Юникода é (LATIN SMALL LETTER E WITH ACUTE, или U+00E9 ). Тем не менее, та же буква может быть представлена в виде пары скалярных величин-стандартной буквой е (LATIN SMALL LETTER E, или U+0065 ), и последующей скалярной величиной COMBINING ACUTE ACCENT (U + 0301). COMBINING ACUTE ACCENT графически присоединяется к предшествующей скалярной величине, превращая e в é , в момент, когда распознающая Юникод символы система, начинает рендер.
В обоих случаях буква é представляется в виде одного значения Character, которое представляет собой расширенный набор графем. В первом случае набор содержит одну скалярную величину; во втором случае две:
let eAcute: Character = "\u{E9}" // é
let combinedEAcute: Character = "\u{65}\u{301}" // e с последующим ́
// eAcute равен é, combinedEAcute равен é
Расширенный набор графем - это удобный способ представления многих сложных печатных символов, как одного значения Character. Например, Hangul звуки из корейского алфавита могут быть представлены либо как предварительно набранные, или наоборот, как разложенные ряды символов. Оба этих варианта определяются как одно Character значение в Swift:
let precomposed: Character = "\u{D55C}"
let decomposed: Character = "\u{1112}\u{1161}\u{11AB}"
//precomposed равен "한", decomposed равен "한"
Расширенный набор графем позволяет скалярам заключающих символов (например, COMBINING ENCLOSING CIRCLE, или U+20DD), заключать другие скаляры Юникода и выглядеть как значение типа Character.
let enclosedEAcute: Character = "\u{E9}\u{20DD}"
// enclosedEAcute равен é⃝
Скалярные величины Юникода для региональных символов могут быть объединены в пары для создания одного Character значения, таких как эта комбинация: REGIONAL INDICATOR SYMBOL LETTER U (U+1F1FA) и REGIONAL INDICATOR SYMBOL LETTER S (U+1F1F8):
let regionalIndicatorForUS: Character = "\u{1F1FA}\u{1F1F8}" // regionalIndicatorForUS равен
Подсчет символов
Чтобы получить количество значений Character в строке, используйте count для строки:
let unusualMenagerie = "Коала  , Улитка
, Улитка  , Пингвин
, Пингвин  , Верблюд
, Верблюд  "
print("unusualMenagerie содержит \(unusualMenagerie.count) символов")
// Выведет "unusualMenagerie содержит 39 символов"
"
print("unusualMenagerie содержит \(unusualMenagerie.count) символов")
// Выведет "unusualMenagerie содержит 39 символов"
Обратите внимание, что использование расширенных наборов графем для Character значений означает, что конкатенация и модификация не всегда могут повлиять на количество символов в строке.
Например, если вы инициализируете новую строку со словом из четырех символов cafe, а затем добавите COMBINING ACUTE ACCENT (U+0301) в ее конце, то результирующая строка будет по-прежнему иметь количество символов - 4 , с четвертым символом é , а не e:
var word = "cafe"
print("количество символов в слове \(word) равно \(word.count)")
// Выведет "количество символов в слове cafe равно 4"
word += "\u{301}" // COMBINING ACUTE ACCENT, U+0301
print("количество символов в слове \(word) равно \(word.count)")
// Выведет "количество символов в слове café равно 4"
Заметка
Расширенный набор графем может состоять из одной или более скалярных величин Юникода. Это означает, что различные символы, и различное отображение одного и того же символа, могут потребовать разных объемов памяти для хранения. Из-за этого, символы в Swift не занимают одинаковый объем памяти в строке. В результате этого, количество символов в строке не может быть подсчитано без итерации в строке, для определения границ расширенного набора графем. Если вы работаете с особенно длинными значениями строк, имейте ввиду, что свойство count должно итерировать все скалярные величины Юникода в строке для того, чтобы определить символы в этой строке. Количество символов, возвращаемых значением count не всегда совпадает со свойством length у NSString, которое содержит те же символы. Длина NSString основывается на числе 16-битовых блоков кода в UTF-16 представлении строки, а не на количестве расширенных набора графем внутри строки.
Доступ и изменение строки
Вы получаете доступ и меняете строку через ее методы, и свойства, или с помощью синтаксиса сабскрипта.
Индексы строки
Каждое String значение имеет связанный тип индекса: String.Index, что соответствует позиции каждого Character в строке.
Как было упомянуто выше, различные символы могут требовать различные объемы памяти для хранения, поэтому для того, чтобы определить, какой Character в определенной позиции, необходимо итерировать каждую скалярную величину Юникода, от начала или конца этой строки. По этой причине, Swift строки не могут быть проиндексированы целочисленными значениями.
Используйте свойство startIndex для доступа позиции первого Character в String. Свойство endIndex — это позиция после последнего символа в String. В результате, endIndex свойство не является допустимым значением для сабскрипта строки. Если String пустая, то startIndex и endIndex равны.
Вы получаете доступ к индексу до и после указанного индекса при помощи методов index(before:) и index(after:). Для доступа к индексу, расположенного не по соседству с указанным индексом, вы можете использовать метод index(_:offsetBy:) вместо многократного вызова предыдущих методов.
Вы можете использовать синтаксис индекса для доступа Character в определенном индексе String.
let greeting = "Guten Tag!"
greeting[greeting.startIndex]
// G
greeting[greeting.index(before: greeting.endIndex)]
// !
greeting[greeting.index(after: greeting.startIndex)]
// u
let index = greeting.index(greeting.startIndex, offsetBy: 7)
greeting[index]
// a
Попытка доступа к Character в индексе за пределами диапазона строки выдаст сообщение об ошибке выполнения.
greeting[greeting.endIndex] // ошибка
greeting.index(after: endIndex) // ошибка
Используйте свойство indices, чтобы создать Range всех индексов, используемых для доступа к отдельным символам строки.
for index in greeting.indices {
print("\(greeting[index]) ", terminator: " ")
}
// Выведет "G u t e n T a g !"
Заметка
Вы можете использовать свойства startIndex, endIndex и методы index(before:), index(after:) и index(_:offsetBy:) с любым типом, который соответствует протоколу Collection. Это включает в себя String, как и показано тут, различные типы коллекций, например Array, Dictionary и Set.
Добавление и удаление
Для того, чтобы вставить символ в строку по указанному индексу, используйте insert(_:at:) метод, а для того, чтобы вставить содержимое другой строки по указанному индексу, используйте метод insert(contentsOf:at:).
var welcome = "hello"
welcome.insert("!", at: welcome.endIndex)
// welcome теперь равен "hello!"
welcome.insert(contentsOf:" there", at: welcome.index(before: welcome.endIndex))
// welcome теперь равен "hello there!”
Для того, чтобы удалить символ из строки по указанному индексу используйте remove(at:), если вы хотите удалить значения по указанному диапазону индексов, используйте метод removeSubrange(_:):
welcome.remove(at: welcome.index(before: welcome.endIndex))
// welcome теперь равно "hello there"
let range = welcome.index(welcome.endIndex, offsetBy: -6)..<welcome.endIndex
welcome.removeSubrange(range)
// welcome теперь равно "hello”
Заметка
Вы можете использовать методы insert(_:at:), insert(contentsOf:at:), remove(at:) и removeSubrange(_:) с любыми типами, которые соответствуют протоколу RangeReplaceableCollection. Это включает в себя String, как показано тут, а так же коллекции, такие как Array, Dictionary и Set.
Подстроки
Вы можете получить подстроку из строки, например, используя сабскрипт или метод типа и prefix(_:), результат которого возвращает экземпляр подстроки, а не другую строку. Подстроки в Swift имеют практически те же самые методы, что и строки, что означает, что вы можете работать с подстроками так же как и со строками. Однако, в отличие от строк, вы используете подстроки непродолжительное время, пока проводите какие-то манипуляции над строками. Когда вы готовы хранить результат более продолжительное время, то вы конвертируете подстроку в строку. Например:
let greeting = "Hello, world!"
let index = greeting.firstIndex(of: ",") ?? greeting.endIndex
let beginning = greeting[..<index]
// beginning is "Hello"
// Конвертируем в строку для хранения более продолжительное время.
let newString = String(beginning)
Как и строки, каждая подстрока имеет область в памяти, где хранятся символы, создающие эту подстроку. Разница между строками и подстроками в том, что для оптимизации производительности подстрока может использовать часть памяти, используемую для хранения исходной строки или часть памяти, которая используется для хранения другой подстроки. (Строки так же имеют похожую оптимизацию, но если две строки делят между собой память, то они считаются равными.) Это оптимизация означает, что у вас не будет потери производительности через копирование памяти, если вы не изменяете строку или подстроку. Как уже было сказано ранее, подстроки не подходят для долгосрочного хранения, так как они повторно используют хранилище исходной строки. Исходная строка должна находиться в памяти до тех пор, пока одна из ее подстрок все еще используется.
В примере выше и greeting является строкой, которая имеет свою область памяти, где создающие ее символы хранятся. Так как и beginning, является подстрокой от greeting, то она переиспользует память. которую использует greeting. И наоборот, newString является строкой, которая была создана из подстроки и теперь она имеет свое хранилище. Рисунок ниже поможет нам разобраться с этими взаимоотношениями:
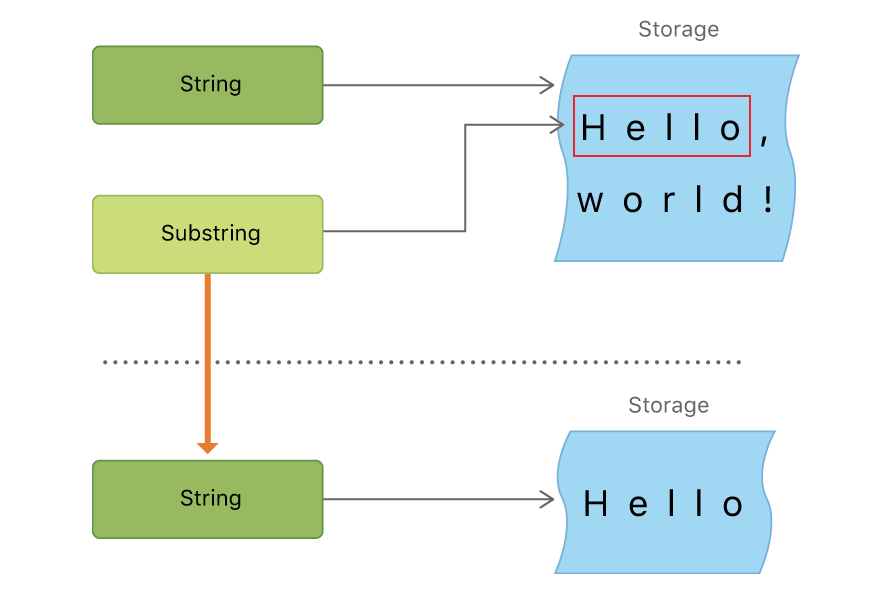
Заметка
И String, и Substring реализуют протокол StringProtocol, что означает, что очень часто бывает удобно для строковых манипуляций принимать значение StringProtocol. Вы можете вызывать такие функции со значением String или Substring.
Сравнение строк
Swift предусматривает три способа сравнения текстовых значений: равенство строк и символов, равенство префиксов, и равенство суффиксов.
Равенство строк и символов
Равенство строк и символов проверяется оператором "равенства" (==) и оператором "неравенства" (!=), что описано в главе «Операторы сравнения»:
let quotation = "Мы с тобой похожи"
let sameQuotation = "Мы с тобой похожи"
if quotation == sameQuotation {
print("Эти строки считаются равными")
}
// Выведет "Эти строки считаются равными"
Два String значения (или два Character значения) считаются равными, если их расширенные наборы графем канонически эквивалентны . Расширенные наборы графем канонически эквивалентны, если они имеют один и тот же языковой смысл и внешний вид, даже если они изначально состоят из разных скалярных величин Юникода.
Например, LATIN SMALL LETTER E WITH ACUTE (U+00E9) канонически эквивалентна LATIN SMALL LETTER E(U+0065) , если за ней следует COMBINING ACUTE ACCENT (U+0301) . Оба этих расширенных набора графем являются допустимыми вариантами представления символа é , и поэтому они считаются канонически эквивалентными:
// "Voulez-vous un café?" используем LATIN SMALL LETTER E WITH ACUTE
let eAcuteQuestion = "Voulez-vous un caf\u{E9}?"
// "Voulez-vous un café?" используем LATIN SMALL LETTER E и COMBINING ACUTE ACCENT
let combinedEAcuteQuestion = "Voulez-vous un caf\u{65}\u{301}?"
if eAcuteQuestion == combinedEAcuteQuestion {
print("Эти строки считаются равными")
}
// Выведет "Эти строки считаются равными"
Наоборот, LATIN CAPITAL LETTER A (U+0041 или "A") , используемый в английском языке, не является эквивалентом CYRILLIC CAPITAL LETTER A (U+0410, или "А"), используемой в русском языке. Символы визуально похожи, но имеют разный языковой смысл:
let latinCapitalLetterA: Character = "\u{41}"
let cyrillicCapitalLetterA: Character = "\u{0410}"
if latinCapitalLetterA != cyrillicCapitalLetterA {
print("Эти строки считаются не равными")
}
// Выведет "Эти строки считаются не равными"
Заметка
Сравнение строк и символов в Swift не зависит от локализации.
Равенство префиксов и суффиксов
Чтобы проверить, имеет ли строка определенный строковый префикс или суффикс, вызовите hasPrefix(_:) и hasSuffix(_:) методы, оба из которых принимают единственный аргумент типа String, и возвращают логическое значение.
В приведенных ниже примерах рассмотрим массив строк, представляющих местоположение сцены в первых двух актах Ромео и Джульетты Шекспира:
let romeoAndJuliet = [
"Act 1 Scene 1: Verona, A public place",
"Act 1 Scene 2: Capulet's mansion",
"Act 1 Scene 3: A room in Capulet's mansion",
"Act 1 Scene 4: A street outside Capulet's mansion",
"Act 1 Scene 5: The Great Hall in Capulet's mansion",
"Act 2 Scene 1: Outside Capulet's mansion",
"Act 2 Scene 2: Capulet's orchard",
"Act 2 Scene 3: Outside Friar Lawrence's cell",
"Act 2 Scene 4: A street in Verona",
"Act 2 Scene 5: Capulet's mansion",
"Act 2 Scene 6: Friar Lawrence's cell"
]
Вы можете использовать hasPrefix(_:) метод с массивом romeoAndJuliet для подсчета количества сцен в первом акте пьесы:
var act1SceneCount = 0
for scene in romeoAndJuliet {
if scene.hasPrefix("Act 1 ") {
act1SceneCount += 1
}
}
print("Всего \(act1SceneCount) сцен в Акте 1")
// Выведет "Всего 5 сцен в Акте 1"
Точно так же, использование hasSuffix(_:) метода для подсчета количества сцен, которые происходят внутри или вокруг особняка Капулетти и клетки монаха Лоренцо:
var mansionCount = 0
var cellCount = 0
for scene in romeoAndJuliet {
if scene.hasSuffix("Capulet's mansion") {
mansionCount += 1
} else if scene.hasSuffix("Friar Lawrence's cell") {
cellCount += 1
}
}
print("\(mansionCount) сцен в особняке; \(cellCount) тюремные сцены")
// выводит "6 сцен в особняке; 2 тюремные сцены"
Заметка
hasPrefix(_:) и hasSuffix(_:) методы используются для символ-к-символу канонического эквивалентного сравнения между расширенными наборами графем в каждой строке, как описано в главе «Равенство строк и символов».
Юникод представления строк
Если строка Юникода записывается в текстовый файл или какое-либо другое хранилище, то скалярные величины Юникода в этой строке кодируются в одном из нескольких Юникод-определенных форм кодирования. Каждая форма кодирует строку мелкими кусками, известными как единица кода. Сюда включены: UTF-8 форма кодирования (которая кодирует строку в 8-битные блоки кода), UTF-16 форма кодирования (которая кодирует строку в качестве 16-битных блоков кода), и UTF-32 форма кодирования (которая кодирует строку в 32-битные единицы кода).
Swift предоставляет несколько разных способов доступа к отображению строк Юникода. Вы можете итерировать строки с for-in, для получения их индивидуальных Character значений, как расширенных наборов графем. Этот процесс описан в разделе "Работа с символами".
Кроме того, доступ к String значению в одном из трех других Юникод-совместимых отображений:
Набор UTF-8 единиц кода (можно получить доступ через свойство строки - utf8)
Набор UTF-16 единиц кода (можно получить доступ через свойство строки - utf16 )
Набор 21-битных скалярных значений Юникода, что эквивалентно форме кодирования UTF-32 (доступ через свойство строки - unicodeScalars)
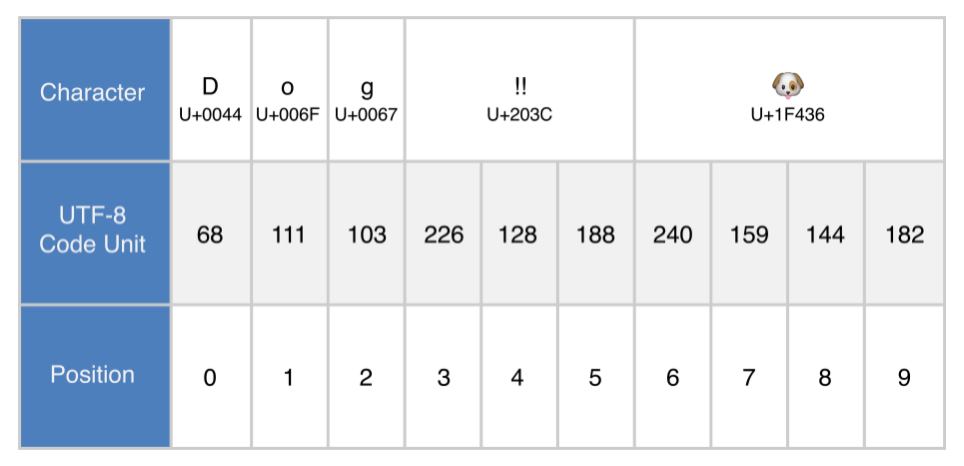
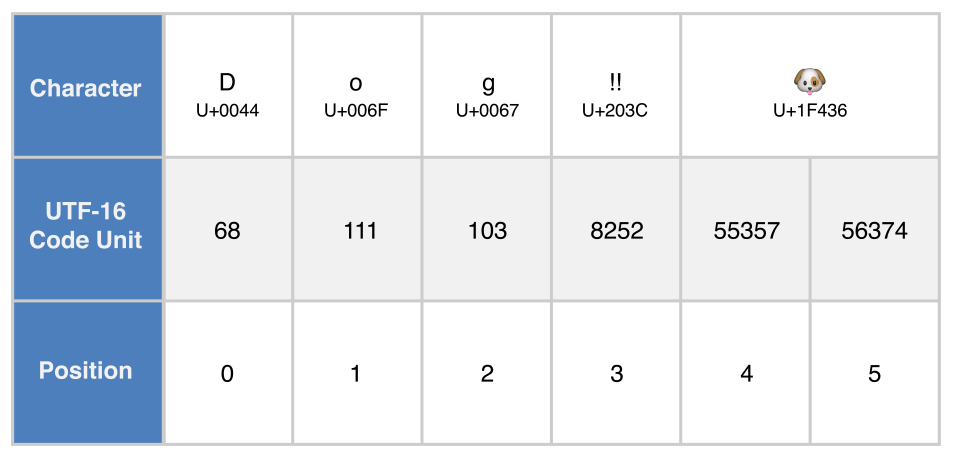
Каждый пример, данный ниже, показывает разное отображение следующей строки, которая состоит из символов 'D', 'o', 'g', '!!' ("DOUBLE EXCLAMATION MARK", "U+203C") и ,  ("DOG FACE", "U+1F436"):
("DOG FACE", "U+1F436"):
let dogString = "Dog‼"
Отображение UTF-8
Вы можете получить доступ к UTF-8 строке, итерируя его свойство utf8. Это свойство имеет тип String.UTF8View, который представляет собой набор значений unsigned 8-bit (UInt8), по одному для каждого байта в представлении UTF-8 строки:
for codeUnit in dogString.utf8 {
print("\(codeUnit) ", terminator: " ")
}
print("")
// 68 111 103 226 128 188 240 159 144 182В приведенном выше примере, первые три десятичных codeUnit значения (68, 111, 103 ) отображают символы D, o, и g , чье UTF-8 отображение такое же, как и в ASCII отображении. Следующие три десятичных codeUnit значения (226, 128, 188 ) являются трех байтным UTF-8 отображением символа DOUBLE EXCLAMATION MARK. Последние четыре codeUnit значения (240, 159, 144, 182 ) являются четырех байтным UTF-8 отображением символа DOG FACE.
Отображение UTF-16
Вы можете получить доступ к UTF-16 строки, итерируя его свойство utf16. Это свойство имеет тип String.UTF16View, который представляет собой набор значений unsigned 16-bit (UInt16), по одному для каждого 16-разрядного блока кода в представлении UTF-16 строки:
for codeUnit in dogString.utf16 {
print("\(codeUnit) ", terminator: " ")
}
print("")
// Выведет "68 111 103 8252 55357 56374 "И опять первые три десятичных codeUnit значения (68, 111, 103 ) отображают символы D, o, и g , чье UTF-16 отображение такое же, как и в строковом отображении UTF-8 (потому что эти скалярные величины Юникода отображают ASCII символы).
Четвертое codeUnit значение (8252) является десятичным эквивалентом шестнадцатеричного 203C, которое отображает скалярную величину Юникода U+203C для символа DOUBLE EXCLAMATION MARK. Этот символ может быть отображен в виде самостоятельной единицы кода в UTF-16.
Пятое и шестое codeUnit значение (55357 и 56374) являются суррогатной парой UTF-16 отображения символа DOG FACE. Эти значения имеют «высоко суррогатное» значение U+D83D (с десятичным значением 55357) и «низко суррогатное» значение U+DC36 (с десятичным значением 56374).
Отображение скалярных величин Юникода 
Вы можете получить доступ к скалярному представлению Unicode значения String путем повторения его свойства unicodeScalars. Это свойство имеет тип UnicodeScalarView, который представляет собой коллекцию значений типа UnicodeScalar.
Каждый UnicodeScalar имеет свойство value, которое возвращает 21-битное значение скаляра, представленное в пределах UInt32:
for scalar in dogString.unicodeScalars {
print("\(scalar.value) ", terminator: " ")
}
print("")
// Выведет "68 111 103 8252 128054 "Свойство value для первых трех десятичных codeUnit значений (68, 111, 103 ) снова отображают символы D, o, и g.
Четвертое codeUnit значение (8252) снова является десятичным эквивалентом шестнадцатеричного 203C, которое отображает скалярную величину Юникода U+203C для символа DOUBLE EXCLAMATION MARK.
Свойство value для пятого и последнего UnicodeScalar, 128054, является десятичным эквивалентом шестнадцатеричного значения 1F436, которое отображает скалярную величину Юникода U+1F436 для символа DOG FACE.
В качестве альтернативы обращения к свойствам value, каждое UnicodeScalar значение также может быть использовано для построения нового String значения, например, с помощью интерполяции строк:
for scalar in dogString.unicodeScalars {
print("\(scalar) ")
}
// D
// o
// g
// ‼
// Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.